PowerDesigner służy do modelowania systemów. Jako bogate narzędzie posiada ono funkcje pozwalające na modelowanie różnych rozwiązań architektonicznych. Główne zastosowania to: modelowanie danych, hurtowni danych, obiektów aplikacji i systemów,procesów biznesowych,architektury korporacyjnej. Przyjrzyjmy się dziedzinie, w której narzędzie jest to najsilniejsze czyli modelowaniu danych. PowerDesigner obsługuje ponad 60 platform bazodanowych.
Model danych jest reprezentacją danych, które są przetwarzane i produkowane przez system. Modelowanie danych wiąże się z reprezentacją obiektów oraz z relacjami występującymi między nimi.
PowerDesigner umożliwia tworzenie konceptualnych, logicznych i fizycznych modeli danych. Modele pozwalają na analizę systemu na wszystkich poziomach abstrakcji.
W tym artykule skupimy się głównie na wykorzystaniu modelowania danych przy tworzeniu bazy danych. Możemy wyróżnić trzy fazy projektowania bazy danych:
- budowanie modelu konceptualnego
- budowanie modelu logicznego
- budowanie modelu fizycznego
Konceptualny model danych (conceptual data model CDM) reprezentuje ogólną strukturę danych w systemie informatycznym, czyli relacje pomiędzy jego obiektami. Model konceptualny jest najbardziej abstrakcyjną formą, dlatego pomija aspekt implementacji fizycznej. Dane są reprezentowane w postaci graficznej za pomocą encji i relacji. Powstaje on a podstawie udokumentowanych wymagań użytkownika, czyli w wyniku etapu analizy.
Logiczny model danych jest na niższym poziomie abstrakcji, ponieważ uwzględnia specyfikację modelu danych ale bez jakichkolwiek uwarunkowań konkretnej implementacji fizycznej.
Fizyczny model danych jest opisem modelu logicznego, w konkretnym środowisku bazodanowym. Uwzględnia on organizację plików, indeksów itp.
Reprezentacją graficzną modelu logicznego danych relacyjnych są diagramy E-R ( Entity Relationship Diagram - Diagram związków encji ) . Obiekty, które modelujemy są reprezentowane przez encje. Są one opisywane za pomocą atrybutów. Pomiędzy encjami występują powiązania. Powiązania wynikają z etapu analizy.
Na poniższym konceptualnym diagramie danych, nauczyciel i student dziedziczą atrybuty z encji Osoba. Między encjami nauczyciel i student występuje relacja jeden do wielu (one-to-many). Oznacza ona, że nauczyciel ma kilku uczniów, ale każdy uczeń ma tylko jednego głównego nauczyciela.
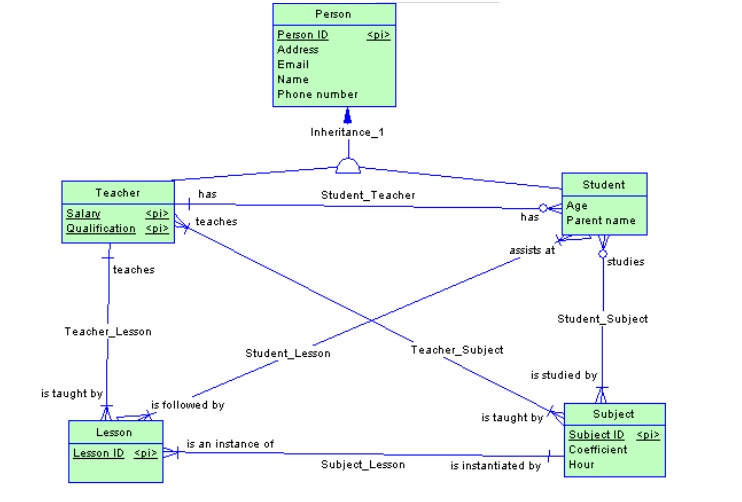
• Nauczyciel może uczyć kilku przedmiotów i przedmiot może być prowadzony przez kilku nauczycieli ( relacja wiele do wielu).
• Nauczyciel może uczyć kilku lekcji i lekcja jest prowadzona tylko przez jednego nauczyciela ( relacja jeden do wielu).
• Student uczęszcza na wiele zajęć i lekcji i jest wielu studentów na lekcji i zajęciach (relacja wiele-do-wielu).
• Student studiuje wiele przedmiotów i przedmiot może być studiowany przez wielu studentów
(relacja wielu do wielu).
• wiele lekcji jest z danego przedmiotu, jeden przedmiot może mieć wiele lekcji (relacja wiele do jednego )
Składowymi modelu danych, czyli diagramu E-R są elementy:
- Encja(entity) - prezentuje wyodrębniony logiczny zestaw danych (np. dane odnoszące się do osoby, samochodu itp)
- Wystąpienie encji(entity instance) - instancja encji, która posiada określone wartości wszystkich atrybutów encji. Każde wystąpienie encji jest identyfikowane jednoznacznie za pomocą niepustego podzbioru atrybutów. (np. wystąpienie encji Uzytkownik jest konkretny użytkownik identyfikowany np. jego loginem )
- Identyfikator encji(entity identifier) - jest to niepusty podzbiór atrybutów encji, który w jednoznaczny sposób identyfikuje każde wystąpienie encji.
- Atrybut(attribute) - opisuje pewną właściwość encji lub związku. (np. dla encji Osoba atrybuty to imie, nazwisko, pesel itp )
- Dziedzina atrybutu (domain) - jest to typ danych jakie mogą przyjmować atrybutu lub zakres wartości dozwolony dla danego atrybutu
- Podklasa(subtype) - jest to encja będąca podzbiorem innej encji (nadklasy). Encja(podklasa) dziedziczy atrybuty i związki nadklasy(np. encja Student dziedziczy po bardziej ogólnej encji Osoba)
- Związek(relationship) - jest to połączenie pomiędzy encjami (dwóch lub więcej). Odzwierciedla współdziałanie pomiędzy encjami. Związek pomiędzy instancjami tej samej klasy naszą nazwe rekurencyjnych. Związek może zawierać atrybuty, które go opisują.
- Liczność(cardinality) - jest to liczba instancji będących w danej relacji. Wyróżniamy ze względu na liczność następujące relacje: jeden do jedn, jeden do wielu, wiele do wiele.
- Opcjonalność (modality) - jak sama nazwa wskazuje czy wystąpienie encji w danej relacji jest wymagane. 0 oznacz opcjonalność wystąpienia, 1 wymóg. ( W naszym przykładzie w relacji Nauczyciel - Student 0 jest reprezentowane przez okrąg, a 1 przez pionową kreskę. Nauczyciel może mieć wielu studentów ale równie dobrze w danym czasie nie musi mieć żadanego, natomiast student musi posiadać nauczyciela )
- Normalizacja - jest to technika analizy zależności pomiędzy elementami danych mająca na celu usuwania nadmiarowych, niespójnych elementów danych.
Pora na utworzenie naszego konceptualnego modelu danych. Po uruchomieniu naszego narzędzia z menu File wybieramy New, a potem New Model.

Następnie możemy zacząć tworzyć nasz model. W tym celu stwórzmy na początku wszystkie encje. Po prawej mamy do dyspozycji paletę narzędzi.

W celu edycji danej encji wystarczy kliknąć na nią dwukrotnie. W zakładce Attributes nadajemy atrybuty dla danej encji.

Każdemu atrybutowi możemy określić, czy ma być kluczem głównym(P), czy jest obowiązkowy(M) czyli brak wartości NULL, i czy ma być wyświetlony(D). Ponadto możemy dla każdego atrybutu określić jego domenę. Klikając prawym przyciskiem myszy na pole numeracji atrybutów, z listy wybierzmy Properties(Właściwości), znajdziemy tam więcej ustawień dotyczących atrybutów.

Aby stworzyć relację wystarczy z palety wybrać ikonę, która reprezentuje relacje i przeciągnąć ją pomiędzy interesującymi nas encjami.

Aby ustawić właściwości relacji wystarczy kliknąć na nią dwukrotnie. W zakładce cardinalities ustawiamy liczność relacji.