JSP - JavaServer Pages jest to technologia, która umożliwia zagnieżdżenie kodu Java w dokumentach HTML. Wcześniej skupialiśmy swoją uwagę na mechanizmie działania serwletów. Generowanie kodu HTML z wykorzystaniem metody println() obiektu PrintWriter. Takie podejście bardzo komplikuje kod i utrudnia korzystanie z narzędzi do tworzenia dokumentów HTML. Podział pracy między tworzeniem wizualnej strony, a tworzeniem logiki jest zachwiany. Odpowiedzią na powyższą wadę serwletów było opracowanie przez firmę Sun technologii JavaServer Pages.
JSP pozwala nam na wstawianie do zwykłego kodu HTML konstrukcji w języku Java - co nie jest obecnie zalecane. Umieszczanie kodu Java w dokumencie HTML odbywa się z wykorzystaniem specjalnych znaczników.

Takie umieszczenie konstrukcji językowych Java w dokumencie JSP nazywamy skryptami. Nie powinniśmy stosować takiego rozwiązania, ponieważ jak wiemy JSP zostało stworzone w celu uniknięcia niewygodnego generowania stron HTML z wykorzystaniem serwletów, a także do rozdzielenia mechanizmów aplikacji webowej czyli warstwy logiki aplikacji od warstwy prezentacji. Skryplety burzą ten podział. Powiedzmy sobie po prostu, że jest to przeszłość. Zamiast nich powinniśmy używać specjalnych znaczników EL i JSTL. Wspomniałem kiedyś, że JSP to tak naprawdę serwlet. Od strony technicznej dokument JSP przy pierwszym uruchomieniu jest przekształcany na serwerze do odpowiadającego im serwletu.

Klient wysyła żądanie pobrania strony, które po przejściu przez serwer HTTP trafia do serwera aplikacji - Web server. Żądanie zostaje przekierowane do kontenera JSP, który znajduje się na serwerze aplikacji. Podczas pierwszego żądania pobrania strony JSP zostaje ona wysłana do translatora JSP. Translator generuje kod wynikowy w postaci klasy serwletu. Kod źródłowy jest przesyłany do kompilatora Java, gdzie zamieniamy jest na Java Byte Code maszyny wirtualnej. Od tej pory ten skompilowany kod czyli tak naprawdę serwlet jest zarządzany przez kontener serwletów.
Skompilowane strony JSP pozostają załadowane do
maszyny wirtualnej Java i kolejne odwołania do tej samej strony nie
wymagają przejścia przez fazę translacji.
Strony JSP mogą odwoływać się do obiektów predefiniowanych w skryptach :
- request - wszystkie parametry wywołania strony JSP (HttpServletRequest)
- response - reprezentuje odpowiedź zwracaną klientowi (HttpServletResponse)
- out - reprezentuje stronę zwracaną klientowi (jsp.JspWriter)
- session - reprezentuje sesję HTTP (http.HttpSession)
- application - reprezentuje kontekst aplikacji (ServletContex)
- config - konfiguracja serwletu (servletConfig)
- pageContext - obiekty, które są w zasięgu widoczności bieżącej strony (jsp.PageContext)
- page - reprezentuje bieżącą stronę (java.lang.Object)
Przyjrzyjmy się skryptom JSP, których jak już wspomniałem nie należy używać. Skrypty są to :
- <%= wyrazenie %> - wyrażenia są one przekazywane na wyjście czyli okno przeglądarki
- <% kod %> - skryplety są umieszczane wewnątrz metody service() serwletu
- <%! kod %> - deklaracje są umieszczane wewnątrz klasy serwletu poza metodami
- page - pozwala m.in. na importowanie klasy, określić język użyty w skryplecie itp.
- include - pozwala na dołączenie innego pliku do treści danej strony
- taglib - jest związana z technologią JSTL, której przyjrzymy się później po omówienie EL
Przykład dyrektywy page:
Jak widzimy dyrektywa taka posiada pewne atrybutu, nie są to wszystkie atrybuty jakie może przyjąć.
Oto najważniejsze ustawienia dyrektywy page:
- contentType - określa typ MIME strony np. text/html
- pageEncoding - kodowanie znaków na stronie
- isErrorPage - określa czy dana strona jest stroną błędu
- errorPage - określa ścieżkę do strony, która ma być wywołana w razie błędu na tej stronie
- session - określa czy na danej stronie jest wykorzystywane mechanizm sesji
- import - pozwala na importowanie klas/pakietów, w celu późniejszego wykorzystania
- isELIgnored - określa, czy elementy języka wyrażeń EL mają być ignorowane na danej stronie
Stwórzmy bardzo prostą aplikację w środowisku NetBeans. Klient wchodząc na stronę poda swoje imię i hasło w formularzu, po zatwierdzeniu danych zostaje wyświetlona strona z imieniem i datą logowania.
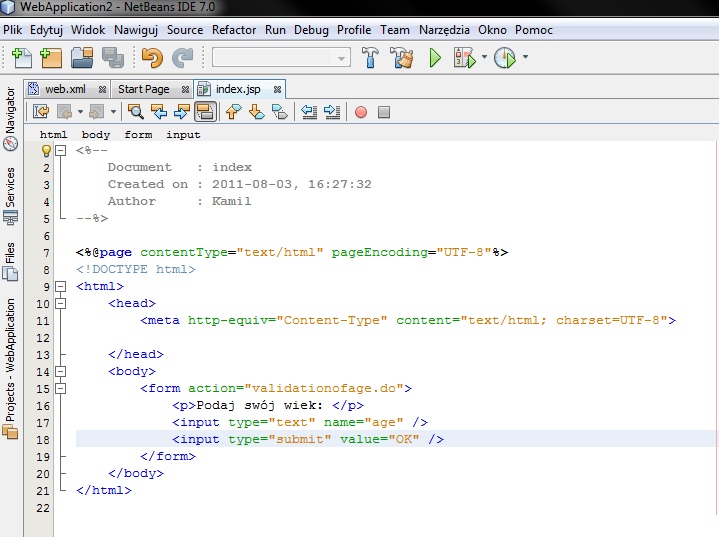
Stwórzmy na początku stronę odpowiadająca za pobranie danych od użytkownika, nazwijmy ją loginpage.jsp:
Strona index.jsp zostanie zmodyfikowana w ten sposób, aby wyświetlała login, który podał klient. Strona wykorzystuje bibliotekę JSTL, powiemy sobie o niej następnym razem. Następuje odczyt w pętli atrybutów sesji. Atrybut ma nazwę User i odwołujemy się do niego przez sessionScope.User .User jest kolekcją zawierającą obiekty klasy User. Zmienna var="user" przechowuje pobrany obiekt z kolekcji. Wyświetlenie nazwy użytkownika i daty logowania odbywa się bardzo prosto: ${user.name} ${user.t} .
Stworzymy też serwlet odpowiedzialny za pobranie danych z formularza i przekierowania żądania do strony index.jsp. W serwlecie korzystamy z mechanizmu sesji. Zapisujemy w niej kolekcję przechowującą obiekty klasy User. Po tym następuje przekierowanie żądania do strony index.jsp.
Obiekt klasy User będzie odzwierciedlać klienta, przechowując jego login, hasło i datę logowania. Taka klasa, która spełnia kilka konwencji głównie takich jak bez parametryczny konstruktor, udostępnianie atrybutów po przez metody pośredniczące get i set nazywamy JavaBean - ziarno kawy. Jak spojrzymy na nasz serwlet to zauważymy, że ustawiamy w zasięgu sesji atrybut o nazwie User będący kolekcją typu ArrayList, przechowującą obiekty klasy User.
Pozostaje, także do skonfigurowania deskryptor wdrożenia:
Nasza aplikacja wygląda w następujący sposób:
Formularz logowania:
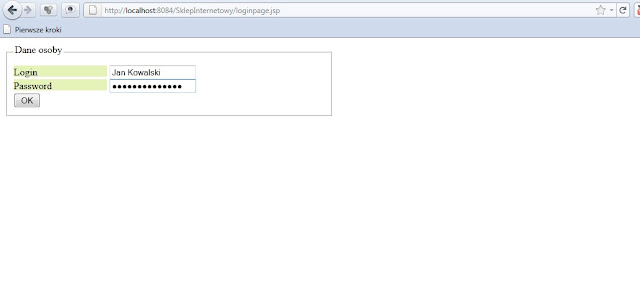
Strona index.jsp, która reprezentuje wprowadzone dane:

W następnych częściach przyjrzymy się EL - językowi wyrażeń, JavaBeans - ziarna kawy, akcjom JSP, standardowej bibliotece tagów JSTL, modelowi JSP 1 i JSP 2 czyli wzorcowi MVC.
Stworzymy też serwlet odpowiedzialny za pobranie danych z formularza i przekierowania żądania do strony index.jsp. W serwlecie korzystamy z mechanizmu sesji. Zapisujemy w niej kolekcję przechowującą obiekty klasy User. Po tym następuje przekierowanie żądania do strony index.jsp.
Obiekt klasy User będzie odzwierciedlać klienta, przechowując jego login, hasło i datę logowania. Taka klasa, która spełnia kilka konwencji głównie takich jak bez parametryczny konstruktor, udostępnianie atrybutów po przez metody pośredniczące get i set nazywamy JavaBean - ziarno kawy. Jak spojrzymy na nasz serwlet to zauważymy, że ustawiamy w zasięgu sesji atrybut o nazwie User będący kolekcją typu ArrayList, przechowującą obiekty klasy User.
Pozostaje, także do skonfigurowania deskryptor wdrożenia:
Nasza aplikacja wygląda w następujący sposób:
Formularz logowania:


W następnych częściach przyjrzymy się EL - językowi wyrażeń, JavaBeans - ziarna kawy, akcjom JSP, standardowej bibliotece tagów JSTL, modelowi JSP 1 i JSP 2 czyli wzorcowi MVC.